ホーム > 一次資料アーカイブ (Primary Sources) > デジタル一次資料アーカイブができるまで
図書館や研究者の方々と話していると、よく「Gale Primary Sources のアーカイブはどのように制作されているのか」というご質問をいただきます。原資料である印刷文書を、どのようにしてテキスト検索可能なデジタル文書に変えるのか。そのプロセスに興味が湧くのは当然のことです。
そこで本記事では、当社のミシェル・ファピアノ(Michelle Fappiano, コンテンツ制作シニアディレクター)、メガン・サリバンとジョー・ウィリアムズ(Megan Sullivan, Joe Williams, 製品マネージャー)、サラ・ホロウェイ(Sarah Holloway, データ・アナリスト)、リック・ライチェキー(Rick Rychecky, ベンダー・マネージャー)にさまざまな質問に答えてもらいました。これらの質問を通じて、デジタルアーカイブ制作の舞台裏のプロセスについて、そして制作チームが Gale の他の部署とどのように連携して製品づくりを進めているのかをご紹介します。
ジョーとメガン(製品マネージャー):デジタルアーカイブの制作工程は、当社の収集担当エディターから始まります。収集担当の仕事は、新しいデジタルアーカイブや既存アーカイブの新モジュールについて構想を練り、関連する資料のコレクションは入手できるか、市場のニーズはあるかといった点に基づいて企画を立てることです。
これというプロジェクトが定まったら、収集担当は企画書をつくり、プロジェクトの承認を得ます。この時点で、アーカイブ資料をスキャンするためのスケジュールも立て始めます。
スキャニングは、特に考慮すべき事情がないかぎり、資料が保管されている図書館などの現場で行うのが普通です。
スキャンが行われている間、開発チームはデジタルアーカイブ用のシステム構築を進め、制作チームはコンテンツのサポートに必要となる新たな機能を洗い出します。こうしておくことで、スキャンされた資料がデータ変換業者に送られ、当社コンテンツチームの手で索引やメタデータが付与されたのち、アーカイブに取り込めるようになります。
データを取り込んだら、リリース時に正しく機能するよう、コンテンツとアーカイブ構造を厳しく検査します。
リック(ベンダー・マネージャー):アーカイブ制作のスキャン工程は、原資料そのものから始まります。すなわち、資料の中身やタイプに応じて制作フローが決まってくるのです。当社の収集担当エディターチームは、企画中の製品のニーズに最も合った資料コレクションを世界中から選び出します。そうしたコレクションは、図書館、大学、歴史学会、博物館など、さまざまな場所に収蔵されています。
コレクションについて契約が交わされると、当社編集スタッフから、タイトル、巻数、フォルダー、書架記号、書誌IDなどを記した目録またはスキャンリストが送られてきます。こうしたデータはMARC(機械可読目録)記録または資料目録から抽出され、スキャン時に確かに契約どおりの資料を抜き出したかを確認したり、メタデータを作成したりするのに使われます。

資料の選定が正しいことを確認したら、各文書に対して保全レビューと呼ばれるプロセスを行います。これはスキャンを始める前の準備として、資料の状態や、その資料がスキャンに適しているかどうかをチェックする工程と考えてください。このプロセスは通常、原資料を収蔵する図書館の保存担当のスタッフが行います。この時点で、状態が悪い資料、傷みや破損のある資料、または特別な取り扱いの必要な資料については、スキャン工程に入る前に補修を行います。
正確に言えば、すべての文書に保存状態の検査と補修が必要なわけではありません。この工程の目的は、製本の割れや破損、ページの折シワや破れなどを見つけて修正し、ページ角の折れ目を直し、カビや腐食を取り除くことです。補修が完了した資料は、保存処置を必要としない他の資料とともにスキャン業者のもとに送られます。ここからスキャン工程が始まります。
保存状態の検査を経て、特別な取り扱いが必要な資料については所蔵館から要件書が出されます。この要件書には、貴重かつ壊れやすい資料を最善の形で取り扱うための指示が詳しく書かれています。以下に挙げるのは、その一例です。
これでスキャン工程の準備は整ったため、業者の選定プロセスに着手できます。通常は、望ましいスキャン業者数社にプロジェクト詳細を提示し、見積もりを依頼する形となります。この間に、各業者は原資料の所蔵館で実際に資料を査定して、対象資料についてより良く把握し、必要な設備を見きわめ、輸送について詳細を確認します。これは業者にとって資料コレクションを直接確認できる機会となります。このとき重要なのは、コレクションの全容が正しく伝わるサンプルを提示することです。すべての業者が見積もりを提出する機会を得たら、こちらで各社の見積もりを審査し、その案件に最も適した業者を選びます。
スキャンに必要な設備は、原資料のタイプによって判断します。多様な資料に対応するため異なる設備が必要になる場合もありますが、たいていの資料はオーバーヘッドスキャナーでデジタル化できます。ただし、いくつか例外もあります。保存状態が良く、背の構造がしっかりした書物の場合は、ロボットスキャナーを使います。これにより生産スピードを最大限に高め、週間処理量を増やすことができます。大型資料(地図や大判の新聞紙面など)の場合は、地図用スキャナーやフィーダー型スキャナーを使用します。原稿台のサイズによってはオーバーヘッドスキャナーでもデジタル化が可能ですが、その場合は分割スキャンした個々の画像を Photoshop などの編集ソフトを使って組み合わせる処理が必要になります。Gale Primary Sources のコンテンツをデジタル化する際に最も広く使われているのが、オーバーヘッドスキャナーです。オペレーターの頭上に設置されたカメラ(デジタルまたはCCDレンズ)で、高さを調節のうえ、資料を真上から撮影できます。
使用する設備と取り扱い方法が大まかに決まれば、スキャン工程そのものはいたってシンプルです。制作プロセスが円滑に進むよう、オペレーターのもとまで資料を輸送するのは、所蔵館の役目となります。一方オペレーターの役目は、作成したデジタル画像とともに、スキャンした資料を記録・追跡することです。オペレーターは各資料のページ数、撮影日、スキャンする際に有用と思われる備考(たとえば、ページ抜けがある、ノド部分が固い、破損がある、ページの振り方が通常と異なる、など)を報告するよう求められます。こういった特記事項は、社内のコンテンツチームや品質管理業者が資料の全体的な状態を把握できるように、制作管理表に追加されます。
実際のスキャン作業は、工場の製造ラインに近いものがあります。箱、書類ばさみ、書物など、どのような形の資料でも、1つずつ原稿台に乗せてスキャンしていきます。担当業者はスキャン対象資料のタイトルリストを確認しつつ、スキャン工程全体を通じて資料群を追跡・管理します。スキャン担当オペレーターは、箱や書類ばさみに入った資料をすべてスキャンし終えるまで、一つ一つ地道に作業を進めます。
すべてのスキャンが完了したら、品質管理チェックが行われます。デジタル画像が承認されるまで、資料は一時保管しておきます。スキャン画像とともに管理表も当社クラウドにアップロードしてもらい、社内スタッフと品質管理業者がチェックします。このプロセスは1週間に一度、またはあらかじめ取り決めたスケジュールに従って行われます。この納品スケジュールは、スキャン工程の進捗を追跡するうえで役立ちます。スケジュールを立てる際には、いくつかの要素を考慮しなければなりません。たとえば、スキャンする総ページ数、1日の処理能力(これは設備や資料のタイプ、スキャン作業に携わるオペレーターの人数によって決まります)、完成商品のリリース予定日などです。
当社では、スキャンを依頼する業者に、基準となるスキャン仕様書を提示しています。これは業界基準とGaleの社内基準をベースとしたもので、各業者はこの基準を満たすことが求められます。
スキャンされた画像は、スキャン業者によって後処理工程にかけられます。後処理とは、未加工のRAW画像をチェックして、当社の求める標準仕様に合うように品質を高める作業です。この工程には、トリミングや文字の傾き補正(デスキュー)を施すなどしてGaleの仕様に合わせる作業も含まれます。つまり、変換工程に移る前に、加工後の画像が当社の品質要件を100%満たすように徹底するということです。
もし画像が審査を通らなかった場合は、該当するファイルについて再スキャン依頼が出され、品質管理レポート一式がスキャン業者に送られます。スキャン業者はレポートに記された調整を行うか、場合によっては仕様との不一致理由を説明したうえで、二次審査のために画像を再度アップロードします。すべての画像が審査をクリアするまで、このプロセスをくり返します。
「光学文字認識(OCR, Optical Character Recognition)とは、紙文書のスキャンデータやPDFファイル、デジタルカメラで撮影された画像など、さまざまなタイプの文書を、編集・検索が可能なデータ形式に変換する技術です。1
OCRは複雑なアルゴリズムを用いて、印刷文書の画像から個々の文字を認識します。
Galeでは、書物、稿本、電報、新聞など紙文書のスキャン画像がもとになるケースがほとんどです。こうしたスキャン画像は、それ単体では、文書内の情報をたとえば Microsoft Word などで編集・分析することができません。スキャン画像はあくまでも、ラスター画像と呼ばれる黒と白とカラーのドット(点)の集まりに過ぎません。スキャンされた文書からデータを抽出するために、GaleではOCRソフトウェアを使ってページ内の個々の文字を読み取り、それらを組み合わせて単語や文章にします。こうすることで、研究者の方々が元文書の内容にアクセスし編集できるようになります」
- Galeの記事「OCR工程の解説(Explaining the OCR Process)」より抜粋。レイ・バンコスキー(Ray Bankoski)著、2018年
ミシェル(コンテンツ制作シニアディレクター): 全体的な工程に関して言えば、手書きテキスト認識(HTR, Handwritten Text Recognition)とOCRの間に大きな違いはありません。ただ、HTRはまだ新しい技術なので、アウトプットのチェックにはより長い時間をかけています。HTRエンジンで問題が生じやすい箇所がどこかを把握しておくことで、学習やソフトウェア改善でどの部分に注力すればよいかがわかります。HTRがOCRと異なるのは、以下のような点です。
HTRとOCRの一般的な比較:
| HTR | OCR |
|---|---|
| 機械印刷された文字と手書き文字のどちらも認識するよう学習させている | 機械印刷された文字のみ認識できる |
| 手書き文字は書き手や時代によって異なるため、標準的なフォントだけでなく、 より多くの手書きパターンも学習させている |
学習できるのは標準的なフォントのみ |
| レイアウト解析や、段落、行、単語の切り出しが非常に難しい | 構造がはっきり定まっているため、認識しやすい |
| 筆記体の手書き文字は認識が非常に困難であるため、精度は比較的劣る | 手書き文字には対応していない |
| 対応可能な言語が限られている | 多くの言語に対応している |
当社使用のHTRとOCRの詳細比較:
| 機 能 | HTR | OCR |
|---|---|---|
| 印刷および手書き文字スタイルの認識 | 近代、西欧、歴史的文字、ゴシック体の 手書きおよび印刷テキスト |
印刷テキストのみ |
| 傾斜テキスト | 〇 | 〇 |
| 逆向きのテキスト | 〇 | 〇 |
| 入力形式 | マルチページTIFF、TIFF、JP2、JPEG、PDF | マルチページTIFF、TIFF、JP2、JPEG、PDF、PNG、BMP |
| 対応言語 | すべてのラテン文字 | 200言語以上 |
| OCR信頼度 | 〇 | 〇 |
| フォーマッティング | × | 〇 |
| 出力 | JSON、PDF | テキスト、XML、RTF、PDF |

中国近代史シリーズで "Hong Kong"(香港)を検索した際のHTRによるヒットの例。
筆記体で書かれた "Hong Kong" の該当箇所が緑色にハイライトされている。
Galeの記事「OCR工程の解説(Explaining the OCR Process)」(レイ・バンコスキー著、2018年)より:
OCRエンジンは、その文字認識がどの程度正確と予想されるかについての自己採点値を「信頼度(confidence)」レベルとして表します。ABBYY社の説明を以下に紹介しましょう。
レイアウト解析では、テキスト領域、行、個々の文字の座標が検出されます。文字の切り出し後、各文字はさまざまなテキスト認識分類子に基づいて認識されます。2
ある文字画像に対する認識信頼度とは、その画像が実際にその文字を表している確率を示した予測数値です。文字を認識するとき、プログラムはいくつかの認識候補を、信頼値に基づいてランク付けして提示します。たとえば、「e」という文字の画像は以下のように認識される可能性があります。
このなかで最も信頼度の高い候補が認識結果として選ばれます。ただし、文脈(つまり、その文字がどのような単語の一部であるか)や差異比較の結果も、この選択に影響をおよぼします。たとえば、「e」と仮定すると辞書に載っていない単語になり、「c」と仮定すると辞書に載っている単語になる場合、たとえ「c」の信頼度が85でも、こちらが認識結果として採用されます。その他の認識候補は、仮説として取得することができます。
OCR工程の精度を正確に測るのは非常に困難です。データベース内の膨大なOCRページを手作業ですべて確認して精度を割り出しでもしない限り、それは不可能でしょう。原則としては、次のようなことが言えます。
大多数のOCRソフトウェア・サプライヤーは、変換した文字総数あたりの正しい文字数をベースに、パーセンテージで精度を示しています。ただし、これは通常、OCRエンジンが変換しようとする対象が、たとえば本誌の印刷版のように、現代の高品質な文書を完璧にレーザープリントしたものだった場合の数値であるため、非常に誤解を招きやすいと言えます。私たちの経験から言えば、完全自動OCRで5,000文字中の誤認識が1字(信頼度99.98%)以上の精度を得られるのは、対象テキストが1950年代以降の印刷文書だった場合のみです。一方、1900年から1950年頃までのテキストでは、精度95%(100文字中の誤認識が5文字)以上がより通常となります。さらに1900年以前の文書については、精度が85%(100文字中の誤認識が15文字)を超えれば運が良いと言えるでしょう。3 〔Tanner, Muñoz and Ros: "Measuring Mass Text Digitization Quality and Usefulness." D-Lib Magazine, July/August 2009 より〕
このことから、GaleのOCR精度(全体における正しいワード数の割合)はデータベースに応じて85~95%と推定できます。
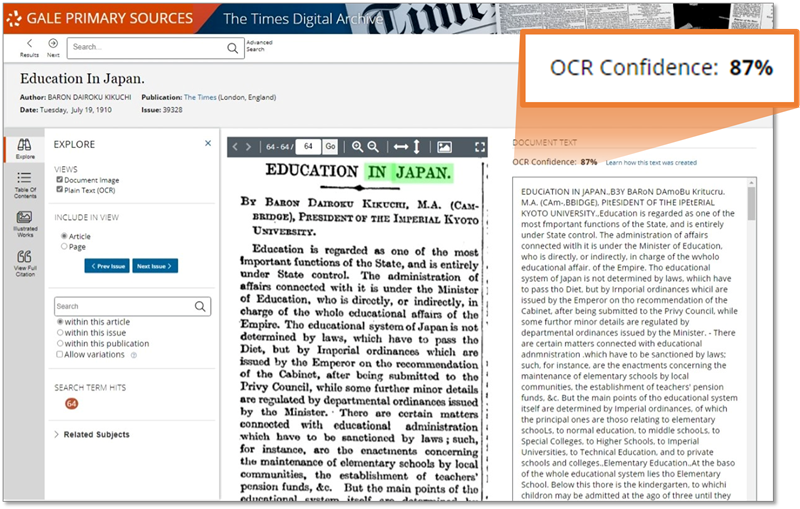
『タイムズ』歴史アーカイブで記事の画像とOCRテキストを並べて表示した例。
この文献のOCR信頼度スコア(OCR Confidence)は「87%」と出ている。
ジョーとメガン:Galeのプラットフォーム機能のアイデアの源はさまざまですが、私たちは主にユーザーテストやユーザーの皆様からのフィードバックをもとに新機能の優先度を決めています。通常、お客様との対話や社内テスト、あるいはGaleの検索体験向上を目指すより大きな取り組みのなかでニーズを見きわめ、その解決策をブレインストーミングします。最適なソリューションを立案できたら、多くの場合はまず試作機能を作って、お客様や社内関係者からフィードバックを集めます。これに応じてコンセプトを微調整し、実用的で、目指すニーズに確実に対応できるソリューションを構築するのです。新機能や拡張の望ましい実装の形が固まったら、社内チーム(コンテンツ、開発等)と協力して必要となる作業を見積もり、プロジェクトの優先度を確認できるようにします。そして、最終的には社内の各チームが連携して、新機能や拡張を実装に導きます。
ジョーとメガン:当社では、Galeが独自に維持管理する堅固な統制語彙に従って、コンテンツに索引付けをしています。統制語彙とは、著者、主題、文書や絵図のタイプ、地理的な場所、新聞の欄見出しなど、さまざまなメタデータフィールドや検索索引の基準となるものです。この基準のおかげで、Galeの広大で多様な一次資料群を利用するうえでも検索体験を一元化でき、切れ目のない横断検索が可能になるのです。
さらに、Galeの検索エンジンはOCRテキストや主題索引内の類義語まで範囲を広げて検索するため、人名や用語のバリエーションについても検索が可能です。たとえば、「marriage(結婚)」というキーワードで検索すると、「matrimony(婚姻)」に関する結果も併せて表示されます。この機能をオフにしたいときは、キーワードを引用符で囲んで検索するか、全文を厳密に検索する全文(Entire Document)検索索引を選ぶとよいでしょう。この機能を支えているGaleシソーラスは、社内の図書館学・情報科学のエキスパートによって維持管理されています。
コンテンツの索引付けは自動プロセスで行われた後、コンテンツおよびメタデータそれぞれの専門家による個別の品質管理チェックを受けます。当社では厳格な索引およびメタデータ付与プロセスを採用しており、正確かつ一貫した標準化された枠組みに常に従うよう徹底しています。そうすることで、研究者の方々に最善の検索体験を提供することが可能になります。これはGaleが深く誇りとするところでもあります。

近現代西洋法制史シリーズで「death penalty」(死刑)を検索した例。
同義語の「capital punishment」も合わせて検索されている。
ミシェル:ソースとなるコンテンツは、制作プロセスを通じて何回にもわたり、自動および人の手による品質チェックを受けます。最初の品質チェックは、画像化業者からスキャン画像が納品される際に行われます。すべてのスキャン画像がチェック対象となります。この段階でチェックされるのは、たとえば次のような点です。
スキャン画像が品質チェックに合格したら、資料のデータ取り込み工程に移ります。この作業は当社の契約業者が請け負っており、OCRテキストの作成とメタデータの入力もここで行われます。データ取り込み工程が完了したら、このデータをさらに品質チェックにかけます。品質チェック業者に依頼し、スキャン画像と取り込まれたデータ(OCRテキストとメタデータ)の両方をチェックします。すべてのドキュメントが品質チェックの対象となり、この段階でチェックされるのは、たとえば次のような点です。
上記の品質チェックをクリアしたデータは当社の制作チームに納品されます(バッチごとに週1回または2回のスケジュールで納品)。納品されたデータは、制作ワークフローのシステムで処理されます。このプロセスでは、データを一連の自動検証ルーティンにかけます。たとえば、以下のような処理が行われます。
上記のプロセスが完了したら、最後にもう一度品質チェックを行います。今度は当社の制作チームが、納品データのサンプルを手作業で検査します。
すべての品質チェックをクリアしたデータは、製品データベースにインポートされます。インポート用スクリプトには、取り込みデータがスキーマ規則に準じているかどうかの検証も含まれます。
メガンとジョー:アーカイブがリリースされたら、最終版のデータを保存します。当社では複数のコピーを作成し、異なるサーバーに保存しています。製品チームはこのコンテンツに常時アクセスでき、簡単にデータを取得することができます。場合によっては、お客様からのフィードバックや、新しい索引や機能の追加のため、データに変更を加える必要も出てきます。お客様がコンテンツに継続的にアクセスできるよう、完全なデータ一式が電子学術情報アーカイブの Portico(www.portico.org)に提供されています。
ミシェルのチームによる品質チェックに加えて、データがデジタルアーカイブに取り込まれた時点で、製品管理チームとコンテンツチームもデータを検査し、リリースに向けて異常がないか確認します。また、新しいコンテンツが追加された場合は、開発チーム、製品管理チーム、品質管理チームがアーカイブそのものを数回にわたってテストし、新機能や拡張機能が想定どおりに動作することを確認します。これにより、アーカイブのリリース時に最善の検索体験をご提供できるようにします。
サラ(データ・アナリスト): 制作チームのメンバーには、「典型的な一日」というのがありません。というのも、私たちはタイムゾーンも言語も異なるさまざまな国のさまざまなチームとともに、日々異なるプロジェクトに取り組んでいるからです。そのため、毎日が新しい課題の連続です。
制作チームは収集担当エディターのアイデアを受けて、それをオンラインで実装し、世界中の所蔵機関からデジタル化された資料のアーカイブやコレクションを検索できるようにします。さらに、Gale内外のいくつものチームや業者と協力して、最終製品を形にしていきます。
要件の収集
製品マネージャーからの要望:
製品管理チームからも、さまざまなタイミングで新しい要望や改善要求が寄せられます。製品マネージャーは当社の全プロジェクトに関して、ユーザーからのコメント、フィードバック、提案等をチェックしています。そして、これらの情報すべてを照合し、ユーザーストーリーや要件としてまとめます。プラットフォーム全体を通じて、最も求められている機能を実装するためです。そのためには通常、制作チームが既存のXMLに対して、新たな機能をサポートするための追加、変更、標準化を施す必要があります。その一例が、つい最近実装された「稿本コレクションの閲覧(Browse Collection)」機能です。これはユーザーから一貫して求められてきた機能でした。そこで、ユーザーが目的の資料を簡単に見つけられるよう、稿本資料には必ず稿本番号を明記して、また稿本番号順にソートできる機能を実装してほしいと我々制作チームに要望が寄せられたのです。

英国情報機関の機密解除文書シリーズに搭載された「稿本コレクションの閲覧」機能。原資料所蔵機関(この場合は英国国立公文書館)の文書番号順に資料を閲覧できる。
収集担当エディターからの要望:
収集担当エディターからも新しいアイデアが随時寄せられます。この場合はまずキックオフミーティングを行い、プロジェクトのアイデア、展望、詳細を確認します。どこから着想を得たのか、どのような資料を集めるか、規模はどのくらいか、最終的にどのような形のオンライン・アーカイブになるのか、このアーカイブの特筆すべき点は何か、といったことを話し合います。
続いて、制作チームはメタデータを詳しく調べ、不自然な点や明らかな抜けはないかを確認します。メタデータの構成と所蔵館が作成した目録とを見比べ、なるべく似通った閲覧性を確保することで、ユーザーが目的の資料を見つけやすいようにします。場合によっては、新しい機能やプログラムがどのような形になるかを示したワイヤフレームを作ることもあります。このワイヤフレームは、Word文書にテキストボックスを配置したものから、しっかりと肉付けされた実際的なものまでさまざまです。制作チームでは、寄せられた要望が実現可能なものかどうか、他のアーカイブと整合性が取れているかを確認します。たとえば、フィルタリング用のワードが「U.S.A.」、「United States of America」とアーカイブによって異なることがないよう注意します。
アーカイブの制作
資料の所蔵機関、大学、図書館:
収集担当エディターから構想を示されたら、制作チームは資料を所蔵している機関や大学、図書館の協力を得て、所蔵資料をどのようにスキャンするか、あるいは資料をいかにして持ち出してスキャンするかを検討します。所蔵機関の協力のもと、MARC記録、総目録、メタデータを取得します。場合によっては、スキャンチームが現場でスキャン対象を正確に把握できるように、機関側が資料に目印を付けておいてくれることもあります。また、所蔵機関自らスキャンを行う、あるいは過去に一部資料をすでにスキャン済みである、というケースもあります。この場合は機関側と協力して画像を確保し、当社でチェックできるようにします。コレクションの中には、長年にわたって正しく目録化されていなかったり、必ずしも手入れされていなかったりするものもあります。そのため、制作チームは所蔵館から説明や質問を受け、こちらも同じく説明や質問をしながら、スキャン開始に向けてすべての資料を集める作業に入ります。
スキャニング:
当社では年間平均1,000万ページもの資料をスキャンするため、複数のスキャン業者と契約しています。これらの業者は所蔵機関に赴いて作業したり、運び込まれた資料を自社施設でスキャンしたりしてくれます。私たちは、必要な資料のリストをスキャンチームと所蔵機関の双方に提供します。資料は、書物、小冊子、ビラ、新聞、定期刊行物、雑誌、稿本、巻物、地図、写真など多岐にわたります。そして、どのタイプの資料にも、それぞれ異なる問題や解決法、ワークフローがあります。制作チームはスキャン工程の間、日々スキャン業者からの質問や説明を受けることになります。この工程は短くて3か月、長ければ2年ほど続きます。寄せられる質問や説明はさまざまです。資料に抜けがある、余分な資料が混じっている、重複がある、保存処理が必要な資料がある。さらには、特別な取り扱いを要する資料についての質問(たとえば、1メートル以上ある巻物をどうスキャンするか?)や、脆すぎてスキャンできない資料についての問い合わせもあります。収集担当エディターに確認が必要な質問も多々あります。制作チームはこうした質問のやり取りが円滑に進むよう見守りサポートしつつ、スキャン作業がスケジュール通りに、かつ原寸に近い形で行えるよう工程の進捗をモニタリングします。
続いて、スキャン画像は別の業者に送られ、品質保証プロセスにかけられます。ここでは品質管理業者のもと、画像が正しくスキャンされているか、順序は正しいか、ピントは合っているか、解像度は適切か、ページ抜けはないか、などがチェックされます。このプロセスでも説明や質問がいくつも生じ、制作チームがその対応や取りまとめを担います。
XML(拡張可能マークアップ言語)への変換:
年間平均1,000万ページもの資料を処理するため、当社ではスキャン画像を変換業者に送って処理を依頼しています。さらに、MARC形式のメタデータ、所蔵目録、当社が社内で作成した独自のメタデータ、所蔵機関や図書館内でフリーランサーに制作させた目録などもあわせて提供します。業者は正しいメタデータを正しい画像セットに割り当て、印刷文字と手書き文字のワードをすべてスキャンし、それらすべてのワードの位置座標をページ全体にマッピングします。これにより、スキャン画像内のワードを検索できるようになるだけでなく、そのワードがハイライト表示されるため見つけやすくなるのです。この工程はその規模に応じて、およそ3~9か月かかります。制作チームはこの期間中、やはり毎日のように業者から質問や説明を受けることになります。メタデータやMARC記録の抜けや誤りに関するものから、特別な指示が必要な特殊資料についての質問(たとえば、切手を集めた本にはどの資料タイプを付与すればよいか?)など、その内容はさまざまです。変換業者からXMLと画像データがバッチごとに返送されてきたら、メタデータを確認し、タイトル、著者、刊行日などの情報が正しく取り込まれているかをチェックします。こうした確認作業や品質管理が、制作チームの日々の業務の大半を占めているのです。
開発チームとの協働:
品質チェックを経て、場合によっては修正されたXMLと画像データは、開発および開発処理チームに送られ、コンテンツや画像がプラットフォームにロードされます。このとき、何らかの問題が見つかったり、新しい索引や要件が関わってきたりするときは、私たちも開発チームに協力します。
索引チームとの協働:
ときには、制作チームの範疇外であったり、チームだけでは処理できない要件が追加で求められたりすることもあります。たとえば、特定分野の専門家の力が必要となる場合や、新聞記事に主題を割り振らねばならない場合です。こういったケースでは、制作チームと索引チームが協働します。索引チームは作業内容に応じてXMLまたはメタデータを引き取り、適切な主題をXML内に挿入して返送してくれます。
1 https://www.abbyy.com/en-gb/finereader/what-is-ocr/
2 https://abbyy.technology/en:features:ocr:classifier(現在リンク切れ)
